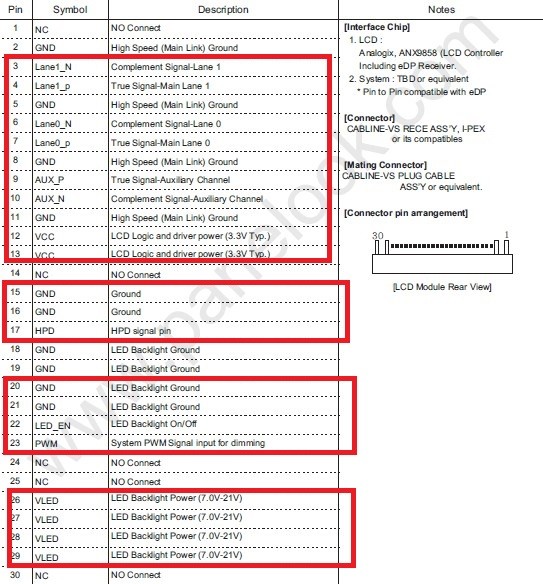
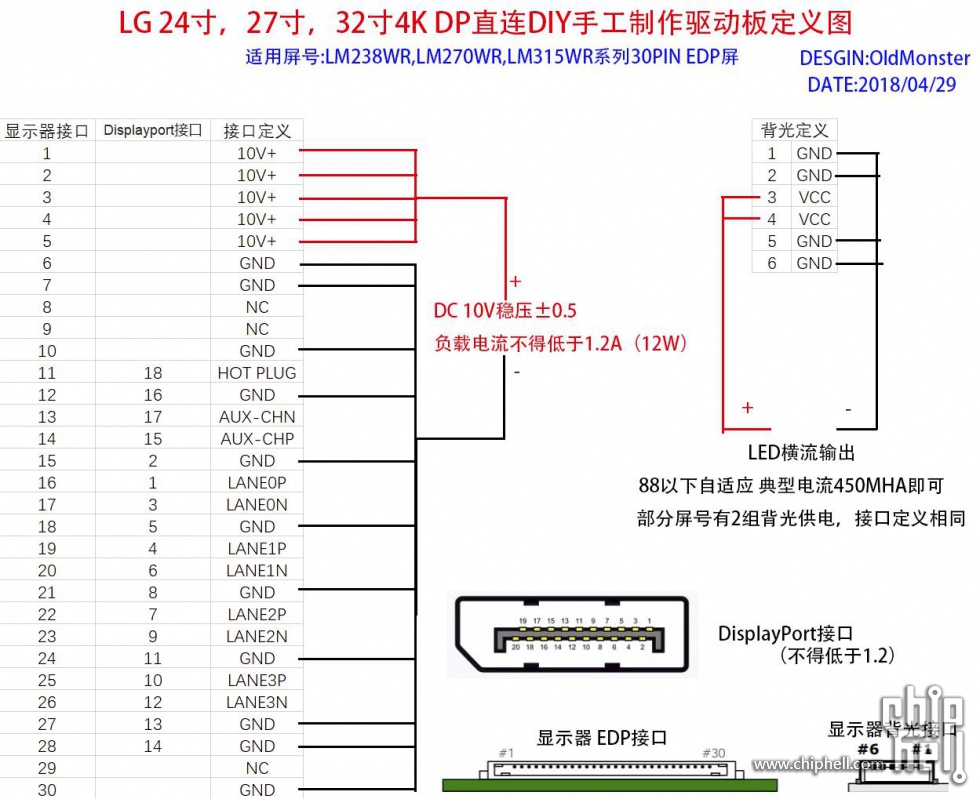
草,又玩了一次李赣梗🤔现在uccfags已经用他们的迷惑行为证实了他们完全没有能力保护他们的亚文化免受无论是hrp还是cuntstantin film的破坏,他们能做的不是抱怨就是内部清洗,更别说向外推广元首亚文化了,我寻思hrp那个只会dssq的人间之屑都比untergangers更能推广元首亚文化,尽管他推广的可能是错误的那部分🙃
当然发生在18年初的hrp和其他untergangers的分家本身就是untergangers社区内卷性的体现,只是那件事情上完全是hrp的锅,但现在我看清楚了,换成raymond chan做社区领袖也解决不了问题,hrp时代那个altright黑客是外部威胁,raymond时代hrp是外部威胁,但很不幸的是我们居然看到了几乎完全一样的反应,hrp在reddit上发个黑屁就吓得他们睾丸都掉了,话说回来uccfags是不是完全不懂公关啊,现在正是黑hrp的关键时刻,直接在他的帖子下面黑屁hrp的黑历史不就行了吗,也许hrpc管理员会删帖,但reddit又不是贴吧,发完评论archive快照一波啊,顺便再开示一次hrp的迫真户籍,而且挂archive上的东西哪怕hrp本人都没法删,如果可能的话可以去那个区块链社交网络上再挂一次,有十万甚至⑨万种方法能让hrp气得像元首一样大叫🤔可惜uccfags一点都不会,他们遇见hrp就怂得像条泰日天,只会拿我出气,而且更生草的是不像他们迫害toilet chan时那么硬核,他们居然连拿我出气都如此费拉,就像perusonafags一样,只会攻击我的短发妹控属性,过于草生
我已经完全不介意被他们驱逐出社区了,毕竟这真的不是我第一次被字面意义上的excommunicated了,上次还是perusonafags,很明显uccfags比perusonafags好不到哪儿去🤔再说了,这么屑的社区不要也罢,说实话现在我又一次很不幸地看透了他们欺软怕硬的费拉本质,我估计以后哪怕他们求我重新加入ucc,我八成也不会鸟他们了
当然迫害raymond chan和uccfags我觉得没啥必要,毕竟我和这群人间之屑打了三年的交道,还是有点感情的,我也许鄙视他们但应该不会迫害他们,除非他们先动手;但stacy blackmon就不一样了,他是所有人的威胁,不仅仅是uccfags,我估计你哪怕是个独立unterganger都有可能被他和他的极端粉丝由于某种迫真原因大肆迫害,如果你™还想认真做元首系列parodies的话,如果你™还在意所谓的“创作自由”的话,那不橄榄hrp你的啥都有可能拜拜了🤔再说了现在他的乐度又上调了一颗星,一个迫真户籍取乐就能让他发动他的生化机器人大肆迫害uccfags(当然仅仅是在twitter和reddit上可能还包括hpw上黑屁而已,但我猜测这两年时间里uccfags没见过这么大的炮杖,全部乱套了),我寻思如果在别的社区拿他的户籍取乐,那个社区搞不好也会被hrp雷普,而他们不见得像uccfags那样弱鸡,hrp搞不好会吃一发大的,估计以所有unterfags包括hrp欺软怕硬的风格,hrp会跪地求饶,那时就非常™生草了🤔
而且现在既然我不是uccfags一员了,我终于可以去搞我的blackmongangin'了,反正好几年只做元首视频实在是无聊,乐hrp才是最生草的事情🤔至于复兴元首梗这件事情,反正uccfags是完全指望不了了,我必须组建一个新的帮派之类的玩意,而且名字我也想好了
Downfall Parody Engineering Group
这个名字完全是参照了JPEG,只不过把专家组改成了工程组,因为它(至少在我的预期里)将完全侧重于工程方面,当然也许由于其初创者的工程师属性
新的元首帮派如果要能完成复兴元首梗的使命,它必须能做到如下的方面:
- 毫无保留地向其成员提供做高质量元首视频需要的全部技术和资源,无论是dpmv教程、乐理教程还是全套的高质量元首视频合集(这个已经有了
- 作为海盗主义者集合,完全无视版权,鼓励所有人上premiere+AE,至少也得vegas,不欢迎wmm废物和android废物
- 开发更高阶的元首视频技术(比如AE脚本或者模板之类的)并同样开源
- 最重要的还是制作质量极高的元首视频,并将我们的技术影响力向其他社区辐射出去(以开源的形式
- 开发能橄榄youtube contentid系统的技术(我知道一个自(迫真)媒体狗又称营销号狗喜欢用的神经网络视频扭曲器,但用来草contentid可能还是不行吧我也不清楚),实现元首视频盈利
- 最好能unuse youtube at all,比如youtube上放被扭曲十万甚至⑨万次的视频,未处理的高清视频挂backblaze上
- 利用一切能利用的手段(包括dssq)来提升DPEG成员视频的访问量和频道的subs
- 面对外部威胁绝不投降,利用一切手段橄榄威胁我们乃至整个元首视频共同体(包括unterfags)的势力,哪怕他是个20万粉丝的大youtuber和前unterganger
- 但那并不意味着莽干,橄榄我们的敌人需要策略,该怂的时候怂,该干的时候干,这才是飞过来传人面对强敌时应该做的
作为迫真新社区领袖,我会尽全力至少做到最前面几条,从而元首梗能在无论youtube还是bilibili上都能像以前那样屌,甚至更屌
antihrp
我说过对付人间之屑有现代主义的对付方法和后现代主义的对付方法,目前看来对toilet chan和stacy chan来说,现代主义已经完全无效了,建设性的批评已经毫无意义因为他们膨胀的ego已经接受不了任何批评,我们不得不使用后现代主义手法了🙄
对李志强来说是做他的鬼畜,但如果是stacy blackmon的话,恐怕除了做鬼畜之外我们还得加个求仁得仁:恁不是喜欢瞎鸡巴钦点任何对恁不满的人是antihrp吗,我们要么让恁见识下什么才是真正的antihrp🤔恁不是自己whois出道了自己还要埋怨别人甚至不惜和uccfags大战三百回合吗,等恁全家户籍都被出了一遍之后,恁再体会下被出道(doxxed)这个单词到底是什么意思🤔恁不是自吹自己是IT Guy吗,建议贵司解雇恁这个连whois protection都不懂的废物,SOFORT🤔
但我这几个月还不准备做这件事,毕竟DPEG我都不见得有心情搞,更别说迫害stacy chan了🤔我也许需要像很多成功(迫真)的untergangers那样先做好irl的事情,然后慢慢搞元hub首鬼畜的事情,其实据我观察,很多untergangers离开ucc之后他们的元首视频水平反而提升了不少,这说明ucc这种屑社区对元首鬼畜事业不仅没有任何促进,反而还拖了后腿🤔我希望我的DPEG如果它有可能成立的话,不要成为那个拖人后腿的屑社区🙃
另外现在uccfags和hrp的战争貌似还没结束,我现在乐hrp的话他的头号舔狗raymond chan(我记得几个小时前他还说了如果hrp对他发火他就对我发火这样的批话,简直就是舔得一无所有的那种舔狗,我在此隔空喊话raymond chan,无论恁怎样卖力口爆hrp的🐔儿,hrp只会把恁和恁的整个ucc当作他的低仿品橄榄)估计会对我极其不满,然后发动整个ucc搞我,而我很不想同时干ucc和hrpc,我更希望他们慢慢自相残杀,所以我现在哪怕乐hrp我也最好不要公然乐
那么什么时候就可以公然乐hrp了?首先我得能合纵连横所有被hrp钦点为antihrp的人们,组成真的antihrp阵营;然后我需要证实哪怕我不在ucc了,hrpc也会因为各种迫真借口来迫害他们;这样首先我乐hrp的时候不会被我以前的战友(口区)反咬一口,其次如果此时raymond chan还在舔的话,我觉得他可以下台了,我和antihrp会把他和整个ucc当作hrp同谋处决🤔然后我就可以搞个blackmonganger chat central,专门乐hrp了,而且我敢肯定这一定比没什么乐子的toiletganger chat central更有意思🤔至于blackmonganger chat central的最终目标,我建议你去看迫真异闻录这款乐子小说里面是怎么乐鸭志田的(手动滑稽
但在接下来找乐子之前,我打算插入一段比较哲学的问题,这来自于我这几年来对unterganger社区和toilet problem的观察;我尽管是个玩世不恭的乐子人(无论把自己当作乐子还是拿别人的痛处取乐),但我希望我人生中有那么几个毫秒的时间能搞点正经(迫真)东西,而这段就是我这几个毫秒的迫真思索的结果
其实这段我应该是写在那篇喜迎5号线开通的文章里面的,但由于太™煞风景了,所以我一直犹豫要不要加;但现在uccfags的这顿事情倒是挺™应景的
the side effect und der untergang of the linguistic imperialism
成都地铁10号线延长段开通的那个下午,我从罗马假日广场吃了顿可能是水饺之后坐上了一辆高升桥站通往新津的10号线地铁车;我可能期望的是能在双流西站后面的站点迫真戏仿perusona 3 the movie #1开场或者诸如此类的场景,但我看到的是非常口区的场景:一个白人又抱着一个妹子,双方都说着英语,然后从双流机场2号航站楼站下车了;让我毫不负责地来猜测一番,他们肯定直接飞到美国去了
看见没有,这就是语言帝国主义:西方世界向全球强行输出英语,这就导致全球所有地方都™会说英语,然后这群白垃圾(也许还有黑垃圾)只会英语就能在任何国家为所欲为,而且我™在成都还要买价值百万的房子,遵循本国对男性的一系列规训才能搞到妹子,而这群垃圾只需要长得凑合就能泡走妹子,还不是泡,而是泡走啊,卧槽,™妹子就完全不用遵循任何规训,因为人都™彻底离开成都了
当然此时10号线列车已经离开了双流西站甚至双流机场2号航站楼站,飞出了地面,我看到了成都极其少有的晴天,感叹这地方实在是太™适合perusona取景了(迫真;而我那完全连不上discord的梯子居然连上了discord,打开又是toilet archive在抱怨他们对toilet chan完全没有办法,我寻思他们之前还拿迫真中文开示了toilet chan的迫真户籍(当然toilet chan可不是什么迫真it guy,他能主动泄露户籍完全是因为他追的那个peachy poke的男友是个toiletganger),不像hrp在他的狗窝里面大吼大叫,toilet chan居然完全没有波动,是什么给了我们的kawaii toilet chan抵抗出道的勇气?为什么hrp被迫真出道就triggered了?
答案还是语言帝国主义:这群废物只会说英语,所以连飞到台南真人快打都做不到,连挖掘toilet chan的本地社交账号(从而可以比如给他妈打教子无方电话之类的,但我估计他妈也完全听不懂英文)都挖掘不出来,而toilet chan这个初中辍学的中华民(迫真)国义务教育(他们也是⑨年)失败品只需要用三个单词里就有一个错别单词的半拉子英语就能天天骚扰得若干个社区叫苦不迭;但hrp™就在英文世界里面,如果他的户籍被比如british first等新纳粹组织知道了,估计有十万甚至⑨万个新纳粹排队去他家真人快打
所以我说过toilet problem就是西方世界自己作的孽,恁用英文征服了全世界,就要做好被全世界反噬的准备;恁可以来亚洲国家随便日批,恁就要忍受自己的妹妹被来自台湾的迫真炼铜术士性骚扰得留下心理阴影,然后在恁国反人类的医疗系统里面一掷千金,而此时恁因为不会说中文拿怹一点办法也没有(手动滑稽
同理,我也可以随便拿hrp的迫真户籍取乐,甚至一不小心又一次引发了uccfags大战hrpfags(上次还是我在ucc刷屏hrp is a fucking cunt并迫真威胁橄榄他的狗窝和youtube频道),但目测他们拿我也没有啥办法,因为我至少不像hrp或者toilet chan,我™是真的it guy;这还不够,我™就是要橄榄hrp,为jennie chan或者unterganger archive报仇这种迫真借口肯定过于迫真,其实嘛,hrp十成甚至⑨成在东南亚嫖过雏鸡,恁在东南亚尽情日批的同时,请尽情吃来自(白人世界观里)四等汉的屎吧!吃到恁的untergang!本日批纳粹野爹将脑控恁的新纳粹迫真基友橄榄恁的屁眼子!
此时我已经到了10号线终点站并开始返回了,我并不是孙笑川的粉丝(但作为迫真后现代主义者,我对孙笑川梗甚至李赣梗是有点了解的)所以对圣地巡礼并没有兴趣,而且成都地铁到新津的票价已经达到了十块甚至⑨块,我只能赶紧赶回去了,搞不好还能赶到校车站下班前问下他们看见我的坑爹a6300兼容电池充电器和两块电池没有,没错我早就开始用虚拟电池系统了,但再过两天我™还要去重庆而我™还搞丢了电池(其实我最后又赶紧买了一套,所以我在去重庆之前搞到了电池,尽管仍然没有什么卵用,因为我组的串联4800mAh锂电池组都没用完),WTF;但无论如何,当另一辆10号线车重返地面时,我的感觉就像makoto yuuki第一次坐电车来到iwatodai city时那样,颅内戏仿perusona 3 the movie #1开场的迷惑行为达到了高潮(迫真:
Dreamless dorm, ticking clock
I walk away from the soundless room
Windless night, moonlight melts
My ghostly shadow to the lukewarm gloom
Nightly dance of bleeding swords
Reminds me that I still liveI will burn my dread
I once ran away from the god of fear
And he chained me to despair
Burn my dread
I'll break the chain
And run till I see the sunlight againI'll lift my face and run to the sunlight
Voiceless town, tapping feet
I clench my fist in pockets tight
Far in mist a tower awaits
Like a merciless tomb, devouring moonlightI will burn my dread
This time I'll grapple down that god of fear and throw him into hell's fire
Burn my dread
I'll shrug the pain and run till I see the sunlight againOh, I will run burning all regret and dread
And I will face the sun with pride of the living
ps. 但那时还不是晚上